实测RTX 5090对比4090显卡AI性能:惊人结果揭晓!

各位 GPU 极客和 AI 爱好者们,大家好。今天我们暂时放下模型,直接进入硬件对决的战场——我们将对比 NVIDIA 的 RTX 5090 和当前王者 RTX 4090,看看它们在微调(fine-tuning)和推理(inferencing)大语言模型(LLMs)这类 AI 任务中的表现。
如果你一直梦想着从模型训练中榨取每一毫秒的性能,那么这篇博客就是为你准备的。几天前发布的RTX 5090搭载了英伟达(NVIDIA)的Blackwell架构,号称性能强到能"烧穿"你的桌面。但它真的能为AI工作负载带来升级吗?
让我们全面剖析——基准测试(benchmarks)、实际场景测试、需要注意的陷阱,以及最终结论。
规格快速对比:5090 vs 4090
从纸面参数来看,5090显卡(GPU)堪称性能怪兽。它拥有更高的浮点运算能力(TFLOPs),更小巧的机身尺寸,以及全方位的硬件升级。
为了实际测试5090是否比4090更好,我进行了3组实验。令人震惊的是,在这3组测试中4090都以巨大优势碾压了5090。下面我们来看看具体结果。
实验设计:三项AI任务,一个共同目标——速度所有实验都使用相同的代码和设置运行——唯一变化的是GPU。以下是实验结果:
1. 使用T5-Large模型总结100篇文章我们使用了谷歌开发的T5-Large(一种文本摘要模型)来处理100篇示例文章。该模型包含约7.7亿个参数(parameters),专门用于生成内容摘要。
使用的代码

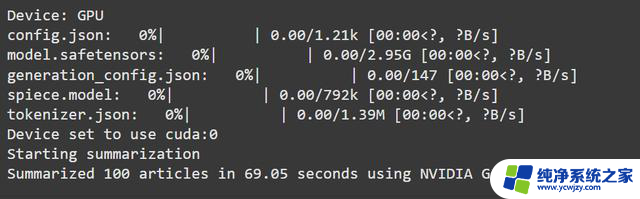

等等...什么?没错。老款的4090反而快了6秒。虽然差距不大,但这就像穿着新球鞋却在短跑比赛中输给了爷爷。
2. 在7,500行数据上微调DistilBERT模型下一步:微调 DistilBERT 进行情感分类。小模型,小数据集——仅训练 5 个周期(epoch)。
你没看错。4090 的速度是5090的两倍。
使用过的代码

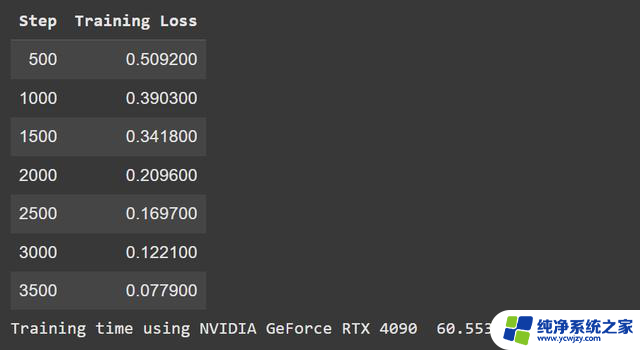
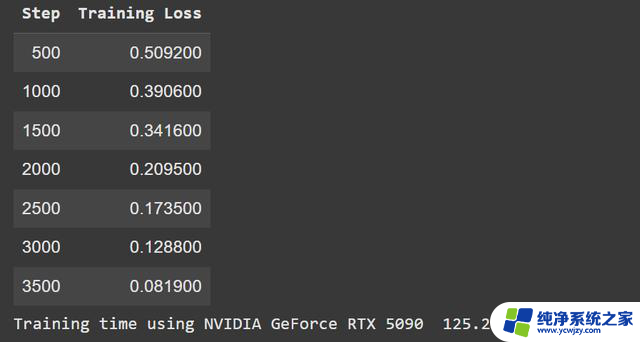
事情开始变得蹊跷了。为什么这款更新、更贵的显卡(pricier card)性能会落后这么多?
3. 使用Stable Diffusion Turbo生成图像接下来我们测试一个更耗显卡资源的任务——用 Stable Diffusion Turbo(稳定扩散加速版)生成100张图片。
使用的代码
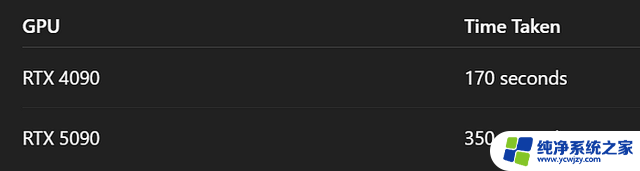
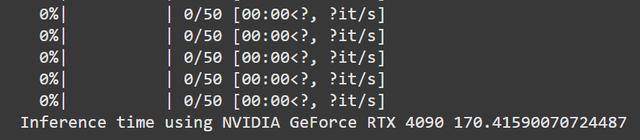
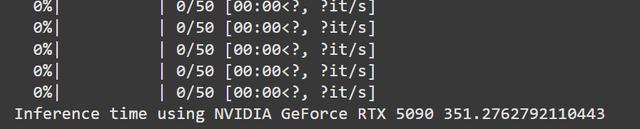
这一次,4090再次碾压了5090,性能领先超过两倍。这到底是怎么回事?
为什么4090仍是AI领域的王者?NVIDIA的RTX 4090显卡自发布以来,始终占据着AI计算性能的榜首位置。这主要归功于以下几个关键因素:
1. 强大的硬件规格
- 16384个CUDA核心(CUDA cores)
- 24GB GDDR6X显存
- 1TB/s的显存带宽
- 高达100TFLOPS的单精度计算性能
2. 完善的软件生态
- 完整支持CUDA和Tensor Core
- 兼容主流AI框架(如TensorFlow、PyTorch)
- 提供专属的DLSS(深度学习超采样)技术
3. 性价比优势
- 相比专业级计算卡(如A100),价格仅为1/5
- 消费级产品中唯一支持PCIe 4.0的旗舰显卡
- 无需额外供电改造即可运行大多数AI模型
4. 开发者友好性
- 支持Windows/Linux双平台
- 完善的驱动程序更新
- 丰富的社区资源和教程
虽然专业计算卡在特定场景下表现更优,但4090凭借其均衡的性能和亲民的价格。依然是大多数AI开发者和研究人员的首选。
让我们直面房间里那只价值2000美元的大象:
1. 库优化(Library Optimization)软件栈(software stack)的重要性远超你的想象。Transformer、Diffusers、Torch这些库已经在RTX 4090上经过实战检验,但它们仍在追赶Blackwell架构的RTX 5090。
要充分发挥 GPU(图形处理器)的性能,硬件和软件都需要升级。
2. CUDA 计算兼容性RTX 5090 引入了新的计算能力(SM 120 和 Hopper 120)。许多旧版本的 PyTorch 和 HuggingFace 工具要么不支持这些功能,要么需要特定版本才能运行。
现实情况:RTX 5090需要最新版本的库文件(library)——但这些版本尚未针对它进行充分优化。典型的先有鸡还是先有蛋问题。
3. 游戏性能 vs AI 优先级英伟达(NVIDIA)的官方宣传将5090显卡定位为游戏/渲染怪兽,宣称其实时渲染性能提升高达30倍。
但对AI来说呢?目前还没有官方的基准测试(benchmark)。这已经很能说明问题了。
结论:2025年该为AI购买RTX 5090吗?如果你的主要需求是游戏、渲染或在Reddit上炫耀,那么RTX 5090绝对是个闪亮、精致又性感的选择。
但如果你正在从事大语言模型(LLM)推理、微调(fine-tuning)或生成式AI相关工作,现实情况是这样的:
因此,除非你是未来兼容性(future-proofing)的狂热爱好者,或者正在为那些等软件库更新后就能发挥5090优势的工作流开发应用,否则目前还是选择4090更合适。
让我们给5090几个月时间慢慢成熟起来。实测RTX 5090对比4090显卡AI性能:惊人结果揭晓!相关教程
- AMD Ryzen AI 9 HX 370性能实测:AI性能大跃进,性能表现惊人
- Win11 24H2 VS Win10 22H2,游戏性能真的更强?测试出炉,结果揭晓!
- 2023年CPU排行榜天梯图:全球最强CPU性能对比排名揭晓
- 华人大神出手,AMD显卡AI“炼丹”能力追上来了,RTX 4090八成性能!
- ROG猛禽RTX 4060“旗舰”显卡测试:性能解锁至163W,强劲性能惊艳亮相
- R5能秒i9?传说能有多离谱:实测AMD 9000系列性能对比
- AMD挑战英伟达,MI325X发布,AI性能超越H200,年更芯片计划揭晓
- 显存翻倍!磐镭RX6500 XT 8G版显卡即将到来,性能提升惊人!
- AMD RX 7900M GPU跑分曝光:Vulkan测试揭示超越移动版RTX 4090显卡9%
- 国产显卡摩尔线程MTT S80再测 时隔半年有何变化,性能提升惊人
- 英伟达独显游戏本用户注意 免费提升性能的方法来了:简单实用的调整技巧
- 不支持Windows 11电脑运行三年,我学到了这些经验
- RTX 5080破发价7944元,英特尔加价、AMD“变形金刚”架构引关注
- Firefox火狐浏览器延长支持Win7/8/8.1系统至2026年3月,用户可放心使用
- 需求不及RX 9070 XT:AMD中国特供RX 9070 GRE已降价700元,抢购价值不容错过
- 需求不及RX 9070 XT:AMD中国特供RX 9070 GRE已降价700元,抢购价值不容错过
热门推荐
微软资讯推荐
win10系统推荐
系统教程推荐